Recently we were having a debate about release processes, and I wrote that deployments are not always equal to releases.
also
deploy!=release
This turned out to be somewhat controversial until we discussed what I specifically meant by deploy and release.
As with all things, agreeing on definitions or understanding what someone means when they use a specific term is essential, so I thought I would write down a short blog post on it.
To start with, a picture helps in my experience:
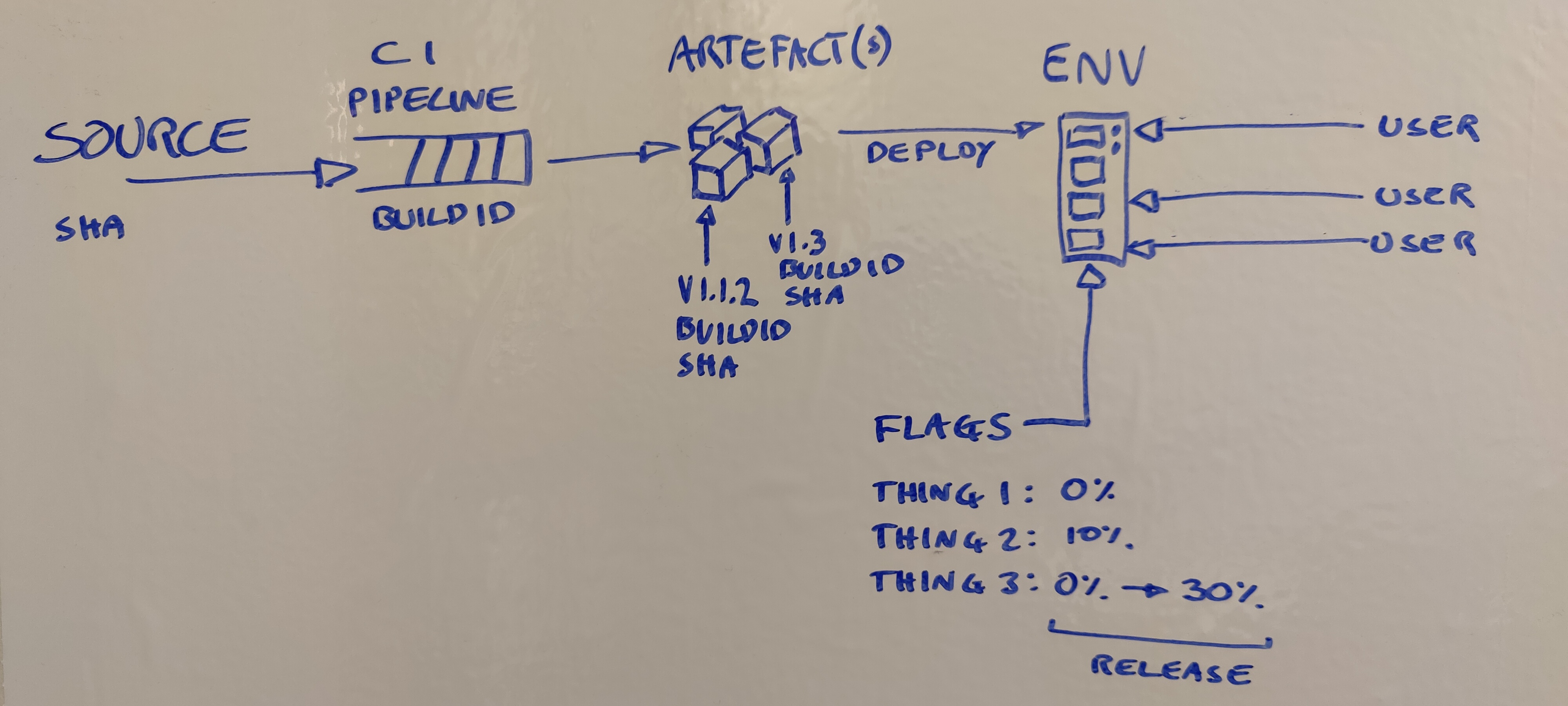
TLDR
Deploy is the act of moving software into an environment and running it.
Release is the process of making a feature visible to a user or subset of users.
Read on for longer descriptions.
Build
A build is a process, usually run in a central CI system, which produces one or many artefacts. A build process can consist of testing, linting, compilation, transpilation, or any other number of steps.
Artefact
An artefact is the result of the build. It has a version, and can be deployed to an environment. An artefact can contain many features which can be uniquely controlled.
It should also have metadata embedded in it to link it back to the build which produced it and also to the source it was built from.
If a build is producing multiple different versioned artefacts, having a way to link them all to the same process is important.
Version
A version is an identifier which uniquely labels an artefact. This can be a chosen format such as SemVer, a datestamp, or a commit hash. It could also be an auto-incrementing build counter.
Deploy
The process of getting an artifact into an environment. Doesn’t necessarily cause any visible changes to a user or client of the application.
Environment
A location running the application. An environment may have multiple applications running, making up one complete product.
Release
Release is switching on (or off) a feature to users, independent of deploy. This is usually done with Feature Flags, and can mean releasing to all users, or just a subset (either a random sample or specific users.)
You can also automate feature rollout by combining it with your observability data, rolling out to more users over time if, for example, error rates don’t increase.