One of the reasons I prefer Pulumi over Terraform is the additional control I have over my processes due to the fact that it’s a programming language.
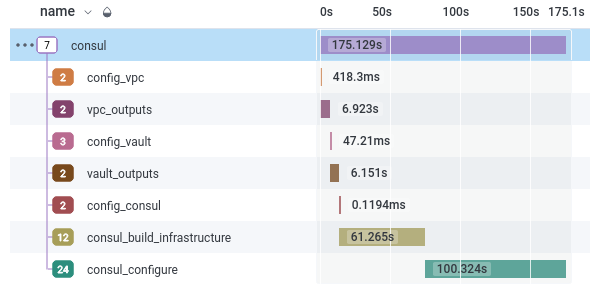
For example, I have a CLI, that creates a cluster of machines for a user; the machines use IAM Authentication with Vault so that they can request certificates on boot. The trouble with this application is that it is slow; it takes 175 seconds on average to provision the machines, write the IAM information to Vault, and then re-run the cloud-init script on all the machines in the cluster (as when they first booted, the configuration hadn’t been written to Vault yet.) so that they can request a certificate. The process is roughly this:
- Create infrastructure
- Write configuration to Vault
- Wait for the machines to be ready
- Wait for SSH
- Re-run cloud-init
The CLI can’t write the configuration to Vault before the machines boot, as the configuration values are from the same infrastructure stack as the machines themselves. You can see the process in the Honeycomb trace UI (with more details about what infra is created thanks to my pulumi-honeycomb stream adaptor):
I don’t want to make two separate stacks for this, one containing IAM Roles and other configuration data, the other containing all the other infrastructure (load balancers, auto-scale groups, etc.) But what if I could dynamically change what the stack does?
By adding an IsInit property to the configuration of the stack, we can change the pulumi program to return early when the value of IsInit is true, meaning we only create the minimal amount of infrastructure for the configuration call to succeed:
func DefineInfrastructure(ctx *pulumi.Context, cfg *ClusterConfiguration) error {
role, err := iam.NewRole(ctx, Name+"-iam-role", &iam.RoleArgs{
NamePrefix: pulumi.String(Name),
AssumeRolePolicy: allowEc2Json,
})
_, err = iam.NewRolePolicy(ctx, Name+"-iam-policy-cluster", &iam.RolePolicyArgs{
NamePrefix: pulumi.String(Name),
Role: role.ID(),
Policy: findMachinesJson,
})
ctx.Export("role-arn", role.Arn)
if cfg.IsInit {
return nil
}
asg, err := autoscaling.NewGroup(ctx, Name+"-asg", &autoscaling.GroupArgs{
LaunchConfiguration: createLaunchConfiguration(ctx, cfg, role),
VpcZoneIdentifiers: cfg.ZoneIdentifiers,
DesiredCapacity: cfg.ClusterSize,
MinSize: cfg.ClusterSize,
MaxSize: cfg.ClusterSize,
})
ctx.Export("asg-name", asg.Name)
return nil
}
Now that the stack can be run to create only partial infrastructure, the process changes to this:
- Create minimal infrastructure
- Write configuration to Vault
- Create remaining infrastructure
But is the new process faster? I had hoped it would be a little faster, as waiting for cloud-init and SSH can take a while, and thankfully, it is significantly faster. It takes on average 98 seconds, so around 77 seconds faster.
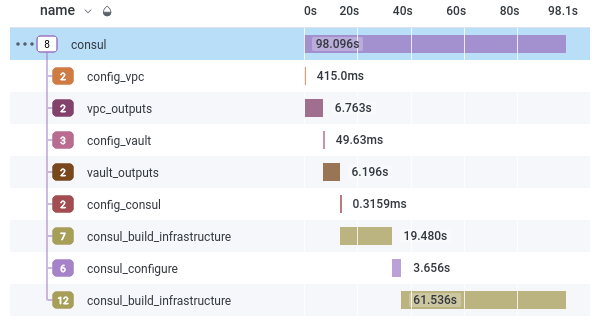
Comparing the before and after traces, I can see that the additional pulumi call adds 20 seconds to the processes, but the consul_configure span drops from 100 seconds to 3.5, which is quite the speed increase.
What about Terraform?
This is still possible to do with a terraform stack, but not in a pleasant way; in pulumi I can return early from the infra function, but with terraform, I would have to add a count = var.is_init ? 0 : 1 to every resource I didn’t want to create up front, which quickly becomes unwieldy.
There is also the downside of not being able to embed the Terraform inside a CLI tool like I can with Pulumi.
Overall, I am happy with how this has turned out. The diff for enabling this optimisation is 3 files changed, 15 insertions, 7 deletions, which included some explanatory comments!