Before I start on this, I want to make it clear that if you can buy Honeycomb, you should. Outlined below is how I started to add observability to an existing codebase which already had the ELK stack available, and was unable to use Honeycomb. My hope, in this case, is that I can demonstrate how much value observability gives, and also show how much more value you would get with an excellent tool, such as Honeycomb.
With that said, what is observability, how is it different to logging (and metrics), and why should you care?
If you already know, or would rather skip to the implementation, jump to Implementing with Elastic Search.
What is it?
The term Observability comes from systems engineering and is how you can determine the behaviour of the entire system from its outputs. In our case, this means the events we emit while processing requests. If we look at (my) hierarchy of monitoring, you can see that it starts with logging, with the next steps up being to output structured logs, then centralising those logs (no more SSHing into random hosts), and finally onto events:
logs < structured logs < centralised structured logs < events (observability)
The Problem with Logs and Metrics
With logs, you are writing out many lines as your process runs, which has a few problems, the primary being that you are often looking for data which is absent.
How many times have you been looking through many lines of logs, before realising “oh, the line about cache invalidation is missing, which means…”. It is much harder to notice data which is absent than data which is present, but with an unexpected value.
The second problem is the size of the logs saved. Logs, especially structured ones, contain a lot of useful information, such as request ids, session ids, paths, versions, host data, and anything else interesting. The majority of these fields are repeated for every log entry in the system, and that means they need to be stored and queryable at some point. Often, this is solved by deleting historical data, or sampling at write time, both of which cause data loss, and you are back to trying to notice data which isn’t there.
Metrics exhibit the data loss problem by design. Metrics are deliberately aggregated client-side and then shipped to storage. The numbers you get from metrics can be useful, but when you look at where they come from, it becomes evident that they are just a projection of logs themselves. How many codebases have you read where every loggger.Info("...", props); line is followed (or preceded) by stats.increment("some_counter)?
So What is an Event?
An Event is a structured piece of data, with as much information about the current request in it as possible. The difference is that you emit one event per request per service, if you are doing microservices. You create an event at the beginning of handling a request and send it somewhere at the end of the request (whether successful or unsuccessful).
For things like background tasks, again, emitting one event per execution, and in well-structured monoliths, one event per request per component.
This doesn’t sound like much of a difference, until you start writing your code to add interesting properties to the event, rather than log lines. We want to store as much high cardinality data as possible (so anything unique, or nearly unique), the more of it, the better, as it lets us slice and dice our events by anything at a later time (e.g. by requestid, userid, endpoint paths, url parameters, http method, etc.)
Looking at the caching example mentioned above, before we had this:
func handleRequest(request *Request) {
now := time.Now()
if cache[request.UserID] == nil || cache[request.UserID].IsStale(now) {
logger.Write("Cache miss for user", request.UserID))
stats.Increment("cache_misses")
fillCache(cache, request.UserID)
}
//...
stats.set("request_duration", time.Since(now))
}
When the user is in the cache, there is no logline written, which is fine when everything is working. However, when something unexpected happens, like daylight savings time or sudden clock drift, and suddenly all cache entries are never stale. You have a decrease in latency (which looks good), your cache_misses counter goes down (looks good), but your data is older than you realised, and bad things are happening down the line.
If you were to write this function with observability in mind, you might write something like this instead:
func handleRequest(request *Request) {
ev := libhoney.NewEvent()
defer ev.Send()
now := time.Now()
ev.Timestamp = now
ev.Add(map[string]interface{}{
"request_id": request.ID,
"request_path": request.Path,
"request_method": request.method,
"user_id": request.UserID,
"cache_size": len(cache),
})
userData, found := cache[request.UserID]
ev.AddField("cache_hit", found)
if !found || userData.IsStale(now) {
userData = fillCache(ev, cache, request.UserID)
}
ev.AddField("cache_expires", userData.CacheUntil)
ev.AddField("cache_is_stale", userData.IsStale(now))
//...
ev.AddField("request_duration_ms", time.Since(now) / time.Millisecond)
}
The resulting event will contain enough information so that in the future when a bug is introduced, you will be able to look at your events and see that yes, while request_duration_ms has gone down and cache_hit has gone up, all the events have cache_is_stale=false with cache_expires times much older than they should be.
So this is the value add of Observability: Answering Unknown Unknowns; the questions you didn’t know you needed to ask.
Implementing with Elastic Search
I won’t cover how to set up and manage the ELK stack (as my opinion is that you should pay someone else to run it. Don’t waste your engineering effort.) I will assume you have a way to get information from stdout of a process into ElasticSearch somehow (I usually use piping to Filebeat, which forwards to LogStash, which processes and pushes into ElasticSearch).
Besides, the code is the important part. This is all written in Go, but I gather you can do similar to NodeJS apps etc. We will use Honeycomb’s [Libhoney-go] package to do the heavy lifting, and supply a custom Transmission. The following is the important part of a custom stdout write (loosely based on libhoney’s WriterSender):
func (w *JsonSender) Add(ev *transmission.Event) {
ev.Data["@timestamp"] = ev.Timestamp
content, _ := json.Marshal(ev.Data)
content = append(content, '\n')
w.Lock()
defer w.Unlock()
w.Writer.Write(content)
w.SendResponse(transmission.Response{
Metadata: ev.Metadata,
})
}
The key difference here is that I am only serialising the .Data property of the Event, and am inserting an extra @timestamp key to make my event structure conform to the standard LogStash pattern.
All that remains to do is configure libhoney to use the custom sender:
libhoney.Init(libhoney.Config{
Transmission: &JsonSender{Writer: os.Stdout},
Dataset: "my-api",
})
Running your service, you would start to see json objects on stdout which look something like this:
{
"@timestamp": "2020-03-15T14:51:43.041744363+02:00",
"request_id": "7f46b313-0a37-457c-9727-b6fdc8c87733",
"request_path": "/api/user/dashboard",
"request_method": "GET",
"user_id": "e6baf70f-9812-4cff-94e9-80a308077955",
"cache_size": 86,
"cache_hit": true,
"cache_expires": "2020-03-15T15:02:17.045625680+02:00",
"cache_is_stale": false,
"request_duration_ms": 17
}
There are no message fields for you to read, but you can see everything which happened in this method; whether the user was found in the cache, how big the cache was etc.
Now if we push that into ElasticSearch, we can filter by any of the values in the event; in this case, I filtered by user_id and added columns for all the cache properties.
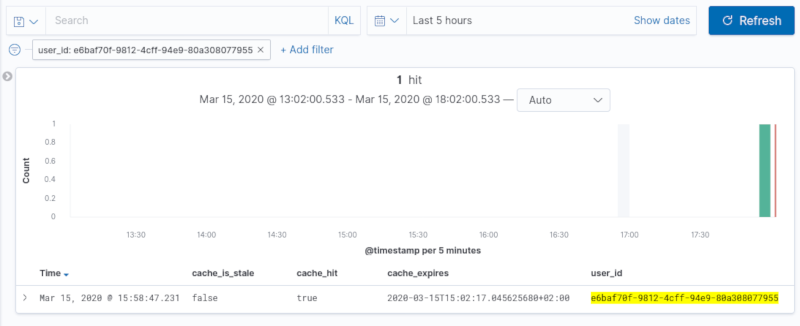
Now everything is in one place; you can slice and dice your data and figure out what exactly is going on. You can even write some metrics off your event queries if you want!
Improvements & Caveats
The main caveat is that pushing this into ElasticSearch is not as good as what you get from Honeycomb - It is just an improvement on logging messages and enables you to demonstrate the value of observability easily.
Once you’ve demonstrated how useful observability is, the next step is to migrate to Honeycomb and get even more value.
I have written the word Honeycomb a lot in this post (9 times so far), but I want to stress that it is observability that we are after and that Honeycomb is an implementation detail. It also happens to be the only real observability tooling (although Lightstep, kind of.)
And let’s not get started on the “3 pillars of observability” bullshit being peddled by other vendors.