Well, for Applications & Services at least. For libraries, SemVer is the way to go, assuming you can agree on what a breaking change is defined as.
But when it comes to Applications (or SaaS products, websites, etc.) SemVer starts to break down. The problem starts with the most obvious: What is a breaking change? How about a minor change?
What’s in a change?
For example, if we were to change the UI of a web application, which caused no backend changes, from the user perspective it is probably a breaking change, but not from the developers perspective. What about changing a backend process, for example, the way the service is billed? How about adding a new step in the middle of an existing process?
These are all hard questions to answer, and I imagine there are many many edge cases and things which are not clear as to what level of change they are.
Clash of the Versions
The next problem stems from the fact that we don’t (often) do Trunk Based Development for applications. We have a long-lived (1-2 weeks) feature branch, which might get pushed to a test environment multiple times as tasks are completed. If we SemVer these deployments, when a bug fix happens on the master branch, we can end up with a version clash, and can’t deploy.
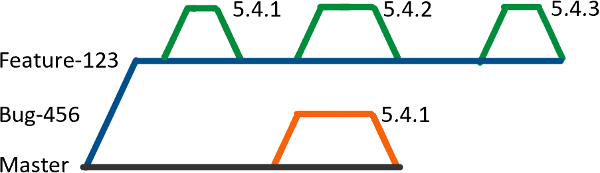
While this is a problem, we can solve it easily - we can use the -pre or -beta suffix for the feature branch, and then remove the suffix and increment the version number when the feature is fully deployed. This, however, is adding a little more complexity to the process - mostly on the human side of things this time.
I would rather avoid the complexity (machine and human) entirely so instead opt for a different solution: Dates.
How about a Date?
Date stamps to the rescue! Our builds now use the following format:
<year>.<month>.<day>.<build_number>
We did consider using the time (represented as .hhmm) instead of the build_number, but it would have been possible to clash if two builds triggered at the same minute, and the build_number is guaranteed uniqueness. By using an automatic format, we gain a few advantages:
- No confusion on whether a change is a major, minor, or patch
- No clashes on multiple branches
- No human input required (marking things as
preorbeta) - Answers the “when was this built” question
What about the libraries?
The libraries have a very different set of requirements, and one versioning scheme doesn’t seem to fit both very well, so there is no point trying to force the matter.