Consul is a great utility to make running your microservice architecture very simple. Amongst other things, it provides Service Discovery, Health Checks, and Configuration. In this post, we are going to be looking at Configuration; not specifically how to read from Consul, but about how we put configuration data into Consul in the first place.
The usual flow for an application using Consul for configuration is as follows:
- App Starts
- Fetches configuration from Consul
- Configures itself
- Registers in Consul for Service Discovery
- Ready
Step 2 is very straightforward - you query the local instance of Consul’s HTTP API, and read the response into your configuration object (If you’re using Microsoft’s Configuration libraries on dotnet core, you can use the Consul.Microsoft.Extensions.Configuration NuGet package).
The question is though, how does the configuration get into Consul in the first place? Obviously, we don’t want this to be a manual process, and as Consul’s HTTP API supports writing too, it doesn’t have to be! But where is the master copy of the configuration data stored? Where it should be! In the repository with your code for the application.
By default, all your configuration values should be going into the base configuration (config.json), and only use the environment specific versions (e.g. config.test.json and config.prod.json) when a value needs to differ in some environments.
Why store config in the repository?
There are many reasons for putting your configuration into a repository alongside the code it relates to, mostly around answering these questions:
- When did this key’s value change?
- Why did this key’s value change?
- Who changed this (do they have more context for why)?
- What values has this key been over time?
- How often is this key changing?
If a value is changing often with reasons (commit messages) such as “scale the thing due to increased traffic” and “scale the thing back down now it’s quiet” that starts to tell you that you should be implementing some kind of autoscaling.
If you find out a key is set incorrectly, you can find out how long it’s been wrong, and maybe discover that the value is not “wrong” but “not right anymore”.
The final piece of this is that you know the value in production will match the value specified - there are no operators accidentally adding a 0 to the end of the number of threads to run etc.
Deployment
Now we just need to get the configuration from the file, and into Consul whenever it changes. As I use Terraform for deploying changes, I just need to update it to write to Consul also.
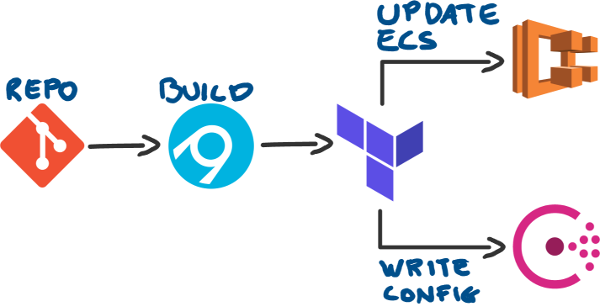
Terraform supports writing to Consul out of the box, however, Terraform can’t directly read parse json files, but we can use the external provider to get around that limitation:
data "external" "config_file" {
program = ["cat", "config.json"]
}
resource "consul_key_prefix" "appsettings" {
path_prefix = "appsettings/testapp/"
subkeys = "${data.external.config_file.result}"
}
If we want to take things a step further, and use our environment specific overrides files, we just need to use the JQ command line tool to merge the two json files, which can be done like so:
jq -s '.[0] * .[1]' config.json config.test.json
Unfortunately, the external provider has a very specific syntax to how it is called, and we can’t just specify the jq command directly. So it needs to go into another file:
#! /bin/bash
jq -s '.[0] * .[1]' "$@"
Finally, we can update the external block to use the new script. You could replace the second file with a merged string containing the current environment (e.g. "config.${var.environment}.json")
data "external" "config_file" {
program = ["bash", "mergeconfigs.sh", "config.json", "config.test.json"]
}
The complete version of this is here in my Terraform Demos repository on GitHub.
What next?
Have a go managing your settings as part of your deployment pipeline! Depending on what tools you are using, you might need to implement your own HTTP posts to the Consul API, but the advantages of automating this task far outweigh the cost of writing some curl commands in my opinion!